Abstract
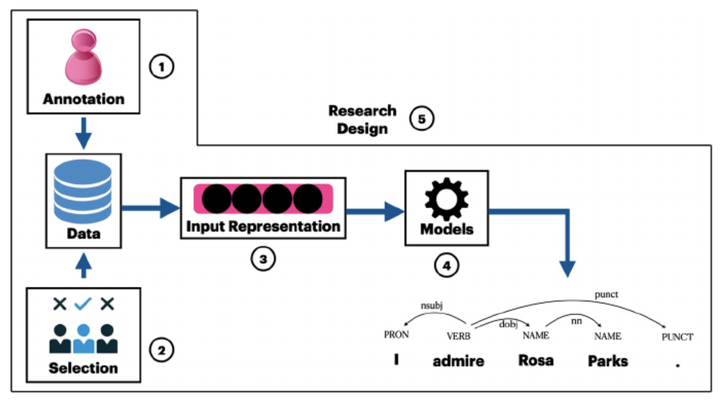
Recently, there has been an increased interest in demographically grounded bias in natural language processing (NLP) applications. Much of the recent work has focused on describing bias and providing an overview of bias in a larger context. Here, we provide a simple, actionable summary of this recent work. We outline five sources where bias can occur in NLP systems: (1) the data, (2) the annotation process, (3) the input representations, (4) the models, and finally (5) the research design (or how we conceptualize our research). We explore each of the bias sources in detail in this article, including examples and links to related work, as well as potential counter-measures.
Type
Publication
Language and Linguistics Compass