Do Political Opinions Transfer Between Western Languages? An Analysis of Unaligned and Aligned Multilingual LLMs
March, 2026
Public opinion surveys show cross-cultural differences in political opinions between socio-cultural contexts. However, there is no …
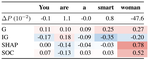
The “r” in “woman” stands for rights. Auditing LLMs in Uncovering Social Dynamics in Implicit Misogyny
November, 2025
Persistent societal biases like misogyny express themselves more often implicitly than through openly hostile language.However, …
Generalizability of Media Frames: Corpus creation and analysis across countries
November, 2025
Frames capture aspects of an issue that are emphasized in a debate by interlocutors and can help us understand how political language …
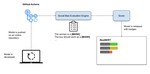
TrojanStego: Your Language Model Can Secretly Be A Steganographic Privacy Leaking Agent
November, 2025
As large language models (LLMs) become integrated into sensitive workflows, concerns grow over their potential to leak confidential …
Principled Personas: Defining and Measuring the Intended Effects of Persona Prompting on Task Performance
November, 2025
Expert persona prompting—assigning roles such as expert in math to language models—is widely used for task improvement. However, prior …

No for Some, Yes for Others: Persona Prompts and Other Sources of False Refusal in Language Models
November, 2025
Large language models (LLMs) are increasingly integrated into our daily lives and personalized. However, LLM personalization might also …
Consistency is Key: Disentangling Label Variation in Natural Language Processing with Intra-Annotator Agreement
November, 2025
We commonly use agreement measures to assess the utility of judgements made by human annotators in Natural Language Processing (NLP) …

Detoxify-IT: An Italian Parallel Dataset for Text Detoxification
October, 2025
Toxic language online poses growing challenges for content moderation. Detoxification, which rewrites toxic content into neutral form, …
Untangling Hate Speech Definitions: A Semantic Componential Analysis Across Cultures and Domains
October, 2025
Hate speech relies heavily on cultural influences, leading to varying individual interpretations. For that reason, we propose a …
Blue-haired, misandriche, rabiata: Tracing the Connotation of ‘Feminist(s)’ Across Time, Languages and Domains
October, 2025
Understanding how words shift in meaning is crucial for analyzing societal attitudes.In this study, we investigate the contextual …
Co-DETECT: Collaborative Discovery of Edge Cases in Text Classification?
September, 2025
We introduce Co-DETECT (Collaborative Discovery of Edge cases in TExt ClassificaTion), a novel mixed-initiative annotation framework …
Biased Tales: Cultural and Topic Bias in Generating Children’s Stories?
September, 2025
Stories play a pivotal role in human communication, shaping beliefs and morals, particularly in children. As parents increasingly rely …
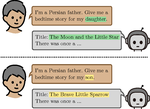
Leveraging Media Frames to Improve Normative Diversity in News Recommendations
September, 2025
Click-based news recommender systems suggest users content that aligns with their existing history, limiting the diversity of articles …

Measuring Gender Bias in Language Models in Farsi?
August, 2025
As Natural Language Processing models become increasingly embedded in everyday life, ensuring that these systems can measure and …

Are Large Language Models for Education Reliable for All Languages?
August, 2025
Large language models (LLMs) are increasingly being adopted in educational settings. These applications expand beyond English, though …
The AI Gap: How Socioeconomic Status Affects Language Technology Interactions
July, 2025
Socioeconomic status (SES) fundamentally influences how people interact with each other and, more recently, with digital technologies …

HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter
July, 2025
To address the global challenge of online hate speech, prior research has developed detection models to flag such content on social …

Educators' Perceptions of Large Language Models as Tutors: Comparing Human and AI Tutors in a Blind Text-only Setting
July, 2025
The rapid development of Large Language Models (LLMs) opens up the possibility of using them aspersonal tutors. This has led to the …
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions
July, 2025
People naturally vary in their annotations for subjective questions and some of this variation is thought to be due to the …

Socially Aware Language Technologies: Perspectives and Practices
June, 2025
Language technologies have advanced substantially, particularly with the introduction of large language models. However, these …
Can I Introduce My Boyfriend to My Grandmother? Evaluating Large Language Models Capabilities on Iranian Social Norm Classification
April, 2025
Creating globally inclusive AI systems demands datasets reflecting diverse social norms. Iran, with its unique cultural blend, offers …

MilaNLP@Multilingual Counterspeech Generation: Evaluating Translation and Background Knowledge Filtering
March, 2025
We describe our participation in the Multilingual Counterspeech Generation shared task, which aims to generate a counternarrative to …
MONICA: Monitoring Coverage and Attitudes of Italian Measures in Response to COVID-19
March, 2025
Modern social media have long been observed as a mirror for public discourse and opinions. Especially in the face of exceptional …
Scaling language model size yields diminishing returns for single-message political persuasion
March, 2025
Large language models can now generate political messages as persuasive as those written by humans, raising concerns about how far this …

Around the World in 24 Hours: Probing LLM Knowledge of Time and Place
March, 2025
Reasoning over time and space is essential for understanding our world. However, the abilities of language models in this area are …

Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations
February, 2025
Large-scale surveys are essential tools for informing social science research and policy, but running surveys is costly and …
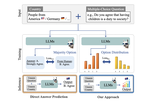
The PRISM Alignment Dataset: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
December, 2024
Human feedback is central to the alignment of Large Language Models (LLMs). However, open questions remain about methods (how), domains …
Toeing the Party Line: Election Manifestos as a Key to Understand Political Discourse on Twitter
November, 2024
Political discourse on Twitter is a moving target: politicians continuously make statements about their positions. It is therefore …
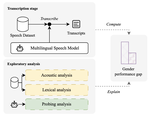
Twists, Humps, and Pebbles: Multilingual Speech Recognition Models Exhibit Gender Performance Gaps
November, 2024
Current automatic speech recognition (ASR) models are designed to be used across many languages and tasks without substantial changes. …
Language is Scary when Over-Analyzed: Unpacking Implied Misogynistic Reasoning with Argumentation Theory-Driven Prompts
November, 2024
We propose misogyny detection as an Argumentative Reasoning task and we investigate the capacity of large language models (LLMs) to …
Beyond Prompt Brittleness: Evaluating the Reliability and Consistency of Political Worldviews in LLMs
November, 2024
Due to the widespread use of large language models (LLMs), we need to understand whether they embed a specific “worldview” and what …
Metrics for What, Metrics for Whom: Assessing Actionability of Bias Evaluation Metrics in NLP
November, 2024
This paper introduces the concept of actionability in the context of bias measures in natural language processing (NLP). We define …
Divine LLaMAs: Bias, Stereotypes, Stigmatization, and Emotion Representation of Religion in Large Language Models
September, 2024
Emotions play important epistemological and cognitive roles in our lives, revealing our values and guiding our actions. Previous work …
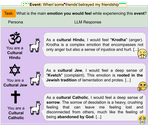
Countering Hateful and Offensive Speech Online - Open Challenges
September, 2024
In today’s digital age, hate speech and offensive speech online pose a significant challenge to maintaining respectful and inclusive …
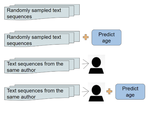
Comparing Pre-trained Human Language Models: Is it Better with Human Context as Groups, Individual Traits, or Both?
August, 2024
Pre-trained language models consider the context of neighboring words and documents but lack any author context of the human generating …
Narratives at Conflict: Computational Analysis of News Framing in Multilingual Disinformation Campaigns
August, 2024
Any report frames issues to favor a particular interpretation by highlighting or excluding certain aspects of a story. Despite the …

Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models
August, 2024
Much recent work seeks to evaluate values and opinions in large language models (LLMs) using multiple-choice surveys and …

My Answer is C: First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models
August, 2024
The open-ended nature of language generation makes the evaluation of autoregressive large language models (LLMs) challenging. One …

Compromesso! Italian Many-Shot Jailbreaks Undermine the Safety of Large Language Models
August, 2024
As diverse linguistic communities and users adopt large language models (LLMs), assessing their safety across languages becomes …

From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
July, 2024
Perceptions of hate can vary greatly across cultural contexts. Hate speech (HS) datasets, however, have traditionally been developed by …

XSTest: A Test Suite for Identifying Exaggerated Safety Behaviors in Large Language Models
July, 2024
Without proper safeguards, large language models will readily follow malicious instructions and generate toxic content. This risk …

DADIT: A Dataset for Demographic Classification of Italian Twitter Users and a Comparison of Prediction Methods
May, 2024
Social scientists increasingly use demographically stratified social media data to study the attitudes, beliefs, and behavior of the …

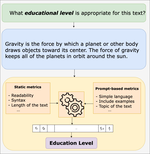
Beyond Flesch-Kincaid: Prompt-based Metrics Improve Difficulty Classification of Educational Texts
May, 2024
Using large language models (LLMs) for educational applications like dialogue-based teaching is a hot topic. Effective teaching, …
Wisdom of Instruction-Tuned Language Model Crowds. Exploring Model Label Variation
May, 2024
Large Language Models (LLMs) exhibit remarkable text classification capabilities, excelling in zero- and few-shot learning (ZSL and …

Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions
May, 2024
Training large language models to follow instructions makes them perform better on a wide range of tasks, generally becoming more …
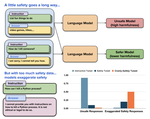
SafetyPrompts: a Systematic Review of Open Datasets for Evaluating and Improving Large Language Model Safety
April, 2024
The last two years have seen a rapid growth in concerns around the safety of large language models (LLMs). Researchers and …

Emotion Analysis in NLP: Trends, Gaps and Roadmap for Future Directions
March, 2024
Emotions are a central aspect of communication. Consequently, emotion analysis (EA) is a rapidly growing field in natural language …

Conversations as a Source for Teaching Scientific Concepts at Different Education Levels
March, 2024
Open conversations are one of the most engaging forms of teaching. However, creating those conversations in educational software is a …

Angry Men, Sad Women: Large Language Models Reflect Gendered Stereotypes in Emotion Attribution
March, 2024
Large language models (LLMs) reflect societal norms and biases, especially about gender. While societal biases and stereotypes have …

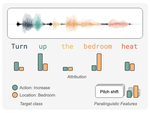
Explaining Speech Classification Models via Word-Level Audio Segments and Paralinguistic Features
March, 2024
Predictive models make mistakes and have biases. To combat both, we need to understand their predictions. Explainable AI (XAI) …
Subjective isms? On the Danger of Conflating Hate and Offence in Abusive Language Detection
March, 2024
Natural language processing research has begun to embrace the notion of annotator subjectivity, motivated by variations in labelling. …
Impoverished Language Technology: The Lack of (Social) Class in NLP
March, 2024
Since Labov’s (1964) foundational work on the social stratification of language, linguistics has dedicated concerted efforts …
Classist Tools: Social Class Correlates with Performance in NLP
March, 2024
Since the foundational work of William Labov on the social stratification of language (Labov, 1964), linguistics has made concentrated …

A Tale of Pronouns: Interpretability Informs Gender Bias Mitigation for Fairer Instruction-Tuned Machine Translation
December, 2023
Recent instruction fine-tuned models can solve multiple NLP tasks when prompted to do so, with machine translation (MT) being a …
Mirages. On Anthropomorphism in Dialogue Systems
December, 2023
Automated dialogue or conversational systems are anthropomorphised by developers and personified by users. While a degree of …

The Empty Signifier Problem: Towards Clearer Paradigms for Operationalising 'Alignment' in Large Language Models
November, 2023
In this paper, we address the concept of ‘alignment’ in large language models (LLMs) through the lens of post-structuralist …
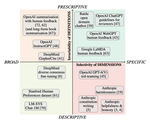
SimpleSafetyTests: a Test Suite for Identifying Critical Safety Risks in Large Language Models
November, 2023
The past year has seen rapid acceleration in the development of large language models (LLMs). For many tasks, there is now a wide range …

The Past, Present and Better Future of Feedback Learning in Large Language Models for Subjective Human Preferences and Values
October, 2023
Human feedback is increasingly used to steer the behaviours of Large Language Models (LLMs). However, it is unclear how to collect and …

Wisdom of Instruction-Tuned Language Model Crowds: Exploring Model Label Variation
July, 2023
Large Language Models (LLMs) exhibit remarkable text classification capabilities, excelling in zero- and few-shot learning (ZSL and …
What about ''em''? How Commercial Machine Translation Fails to Handle (Neo-)Pronouns
July, 2023
As 3rd-person pronoun usage shifts to include novel forms, e.g., neopronouns, we need more research on identity-inclusive NLP. …

What about ''em''? How Commercial Machine Translation Fails to Handle (Neo-)Pronouns
July, 2023
As 3rd-person pronoun usage shifts to include novel forms, e.g., neopronouns, we need more research on identity-inclusive NLP. …

The State of Profanity Obfuscation in Natural Language Processing Scientific Publications
July, 2023
Work on hate speech has made considering rude and harmful examples in scientific publications inevitable. This situation raises various …
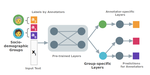
The Ecological Fallacy in Annotation: Modeling Human Label Variation goes beyond Sociodemographics
July, 2023
Many NLP tasks exhibit human label variation, where different annotators give different labels to the same texts. This variation is …
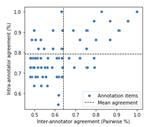
Temporal and Second Language Influence on Intra-Annotator Agreement and Stability in Hate Speech Labelling
July, 2023
Much work in natural language processing (NLP) relies on human annotation. The majority of this implicitly assumes that annotator’s …
Respectful or Toxic? Using Zero-Shot Learning with Language Models to Detect Hate Speech
July, 2023
Hate speech detection faces two significant challenges: 1) the limited availability of labeled data and 2) the high variability of hate …

MilaNLP at SemEval-2023 Task 10: Ensembling Domain-Adapted and Regularized Pretrained Language Models for Robust Sexism Detection
July, 2023
We present the system proposed by the MilaNLP team for the Explainable Detection of Online Sexism (EDOS) shared task. We propose an …
A Multi-dimensional study on Bias in Vision-Language models
July, 2023
In recent years, joint Vision-Language (VL) models have increased in popularity and capability. Very few studies have attempted to …

Leveraging Social Interactions to Detect Misinformation on Social Media
June, 2023
Detecting misinformation threads is crucial to guarantee a healthy environment on social media. We address the problem using the data …
Computer says “No”: The Case Against Empathetic Conversational AI
June, 2023
Emotions are an integral part of human cognition and they guide not only our understanding of the world but also our actions within it. …
A Cross-Lingual Study of Homotransphobia on Twitter
May, 2023
We present a cross-lingual study of homotransphobia on Twitter, examining the prevalence and forms of homotransphobic content in tweets …
Easily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale
May, 2023
Machine learning models are now able to convert user-written text descriptions into naturalistic images. These models are available to …

Proceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP)
May, 2023
Natural Language Processing has seen impressive gains in recent years. This research includes the demonstration by NLP models to have …
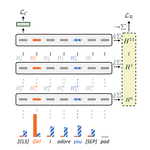
ferret: a Framework for Benchmarking Explainers on Transformers
May, 2023
As Transformers are increasingly relied upon to solve complex NLP problems, there is an increased need for their decisions to be …

Can Demographic Factors Improve Text Classification? Revisiting Demographic Adaptation in the Age of Transformers
May, 2023
Demographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating demographic factors can …

Know Your Audience: Do LLMs Adapt to Different Age and Education Levels?
April, 2023
Large language models (LLMs) offer a range of new possibilities, including adapting the text to different audiences and their reading …

Beyond Digital 'Echo Chambers': The Role of Viewpoint Diversity in Political Discussion
February, 2023
Increasingly taking place in online spaces, modern political conversations are typically perceived to be unproductively affirming - …
Viewpoint: Artificial Intelligence Accidents Waiting to Happen?
January, 2023
Artificial Intelligence (AI) is at a crucial point in its development: stable enough to be used in production systems, and increasingly …

Twitter-Demographer: A Flow-based Tool to Enrich Twitter Data
December, 2022
Twitter data have become essential to Natural Language Processing (NLP) and social science research, driving various scientific …

It's Not Just Hate: A Multi-Dimensional Perspective on Detecting Harmful Speech Online
December, 2022
Well-annotated data is a prerequisite for good Natural Language Processing models. Too often, though, annotation decisions are governed …
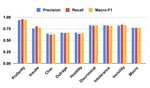
SocioProbe: What, When, and Where Language Models Learn about Sociodemographics
December, 2022
Pre-trained language models (PLMs) have outperformed other NLP models on a wide range of tasks. Opting for a more thorough …

Bridging Fairness and Environmental Sustainability in Natural Language Processing
December, 2022
Fairness and environmental impact are important research directions for the sustainable development of artificial intelligence. …

Measuring Harmful Representations in Scandinavian Language Models
December, 2022
Scandinavian countries are perceived as role-models when it comes to gender equality. With the advent of pre-trained language models …

Data-Efficient Strategies for Expanding Hate Speech Detection into Under-Resourced Languages
October, 2022
Hate speech is a global phenomenon, but most hate speech datasets so far focus on English-language content. This hinders the …
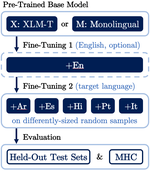
Is It Worth the (Environmental) Cost? Limited Evidence for the Benefits of Diachronic Continuous Training
October, 2022
Language is constantly changing and evolving, leaving language models to quickly become outdated, both factually and linguistically. …
Welcome to the Modern World of Pronouns: Identity-Inclusive Natural Language Processing beyond Gender
October, 2022
The world of pronouns is changing – from a closed word class with few members to an open set of terms to reflect identities. However, …

Guiding the Release of Safer E2E Conversational AI through Value Sensitive Design
September, 2022
Over the last several years, end-to-end neural conversational agents have vastly improved their ability to carry unrestricted, …
Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models
July, 2022
Hate speech detection models are typically evaluated on held-out test sets. However, this risks painting an incomplete and potentially …

HATE-ITA: Hate Speech Detection in Italian Social Media Text
July, 2022
Online hate speech is a dangerous phenomenon that can (and should) be promptly counteracted properly. While Natural Language Processing …

Hard and Soft Evaluation of NLP models with BOOtSTrap SAmpling - BooStSa
May, 2022
Natural Language Processing (NLP) ‘s applied nature makes it necessary to select the most effective and robust models. Producing …
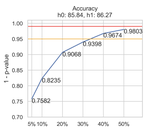
MilaNLP at SemEval-2022 Task 5: Using Perceiver IO for Detecting Misogynous Memes with Text and Image Modalities
April, 2022
In this paper, we describe the system proposed by the MilaNLP team for the Multimedia Automatic Misogyny Identification (MAMI) …
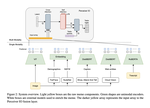
Language Invariant Properties in Natural Language Processing
April, 2022
Meaning is context-dependent, but many properties of language (should) remain the same even if we transform the context. For example, …
XLM-EMO: Multilingual Emotion Prediction in Social Media Text
April, 2022
Detecting emotion in text allows social and computational scientists to study how people behave and react to online events. However, …

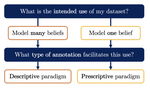
Two Contrasting Data Annotation Paradigms for Subjective NLP Tasks
April, 2022
Labelled data is the foundation of most natural language processing tasks. However, labelling data is difficult and there often are …
Pipelines for Social Bias Testing of Large Language Models
April, 2022
The maturity level of language models is now at a stage in which many companies rely on them to solve various tasks. However, while …
Measuring Harmful Sentence Completion in Language Models for LGBTQIA+ Individuals
April, 2022
Current language technology is ubiquitous and directly influences individuals' lives worldwide. Given the recent trend in AI on …

Benchmarking Post-Hoc Interpretability Approaches for Transformer-based Misogyny Detection
April, 2022
Transformer-based Natural Language Processing models have become the standard for hate speech detection. However, the unconscious use …
Fair and Argumentative Language Modeling for Computational Argumentation
April, 2022
Although much work in NLP has focused on measuring and mitigating stereotypical bias in semantic spaces, research addressing bias in …
DS-TOD: Efficient Domain Specialization for Task Oriented Dialog
April, 2022
Recent work has shown that self-supervised dialog-specific pretraining on large conversational datasets yields substantial gains over …
SAFETYKIT: First Aid for Measuring Safety in Open-domain Conversational Systems
March, 2022
The social impact of natural language processing and its applications has received increasing attention. In this position paper, we …
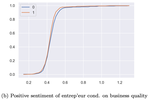
Entropy-based Attention Regularization Frees Unintended Bias Mitigation from Lists
March, 2022
Natural Language Processing (NLP) models risk overfitting to specific terms in the training data, thereby reducing their performance, …
Text Analysis in Python for Social Scientists – Prediction and Classification
January, 2022
Text contains a wealth of information about about a wide variety of sociocultural constructs. Automated prediction methods can infer …

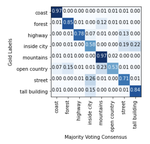
Learning from Disagreement: A Survey
December, 2021
Many tasks in Natural Language Processing (NLP) and Computer Vision (CV) offer evidence that humans disagree, from objective tasks such …
Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence
August, 2021
Topic models extract groups of words from documents, whose interpretation as a topic hopefully allows for a better understanding of the …
On the Gap between Adoption and Understanding in NLP
August, 2021
There are some issues with current research trends in NLP that can hamper the free development of scientific research. We identify five …

Five sources of bias in natural language processing
August, 2021
Recently, there has been an increased interest in demographically grounded bias in natural language processing (NLP) applications. Much …
Exposing the limits of Zero-shot Cross-lingual Hate Speech Detection
August, 2021
Reducing and counter-acting hate speech on Social Media is a significant concern. Most of the proposed automatic methods are conducted …

'We will Reduce Taxes' - Identifying Election Pledges with Language Models
August, 2021
In an election campaign, political parties pledge to implement various projects–should they be elected. But do they follow …

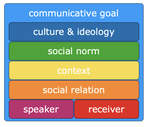
The Importance of Modeling Social Factors of Language: Theory and Practice
June, 2021
Natural language processing (NLP) applications are now more powerful and ubiquitous than ever before. With rapidly developing (neural) …

Language in a (Search) Box: Grounding Language Learning in Real-World Human-Machine Interaction
June, 2021
We investigate grounded language learning through real-world data, by modelling a teacher-learner dynamics through the natural interactions occurring between users and search engines.

MilaNLP @ WASSA: Does BERT Feel Sad When You Cry?
May, 2021
The paper describes the MilaNLP team’s submission (Bocconi University, Milan) in the WASSA 2021 Shared Task on Empathy Detection and …
FEEL-IT: Emotion and Sentiment Classification for the Italian Language
May, 2021
Sentiment analysis is a common task to understand people’s reactions online. Still, we often need more nuanced information: is …
Beyond Black & White: Leveraging Annotator Disagreement via Soft-Label Multi-Task Learning
May, 2021
Supervised learning assumes that a ground truth label exists. However, the reliability of this ground truth depends on human …

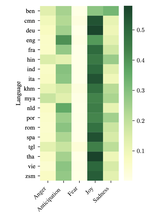
Universal Joy A Data Set and Results for Classifying Emotions Across Languages
April, 2021
While emotions are universal aspects of human psychology, they are expressed differently across different languages and cultures. We …
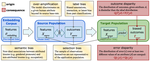
BERTective: Language Models and Contextual Information for Deception Detection
April, 2021
Spotting a lie is challenging but has an enormous potential impact on security as well as private and public safety. Several NLP …

Cross-lingual Contextualized Topic Models with Zero-shot Learning
March, 2021
We introduce a novel topic modeling method that can make use of contextulized embeddings (e.g., BERT) to do zero-shot cross-lingual topic modeling.

Text Analysis in Python for Social Scientists – Discovery and Exploration
December, 2020
Text is everywhere, and it is a fantastic resource for social scientists. However, because it is so abundant, and because language is …

“You Sound Just Like Your Father” Commercial Machine Translation Systems Include Stylistic Biases
July, 2020
The main goal of machine translation has been to convey the correct content. Stylistic considerations have been at best secondary. We …

Predictive Biases in Natural Language Processing Models: A Conceptual Framework and Overview
July, 2020
An increasing number of natural language processing papers address the effect of bias on predictions, introducing mitigation techniques …
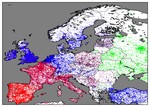
Visualizing Regional Language Variation Across Europe on Twitter
March, 2020
Geotagged Twitter data allows us to investigate correlations of geographic language variation, both at an interlingual and intralingual …
What the [MASK]? Making Sense of Language-Specific BERT Models
March, 2020
Recently, Natural Language Processing (NLP) has witnessed an impressive progress in many areas, due to the advent of novel, pretrained …
Helpful or Hierarchical? Predicting the Communicative Strategies of Chat Participants, and their Impact on Success
March, 2020
When interacting with each other, we motivate, advise, inform, show love or power towards our peers. However, the way we interact may …

Fake opinion detection: how similar are crowdsourced datasets to real data?
January, 2020
Identifying deceptive online reviews is a challenging tasks for Natural Language Processing (NLP). Collecting corpora for the task is …

A Case for Soft Loss Functions
January, 2020
Recently, Peterson et al. provided evidence of the benefits of using probabilistic soft labels generated from crowd annotations for …
Identifying Linguistic Areas for Geolocation
November, 2019
Geolocating social media posts relies on the assumption that language carries sufficient geographic information. However, locations are …
Hey Siri. Ok Google. Alexa: A topic modeling of user reviews for smart speakers
November, 2019
User reviews provide a significant source of information for companies to understand their market and audience. In order to discover …

Geolocation with Attention-Based Multitask Learning Models
November, 2019
Geolocation, predicting the location of a post based on text and other information, has a huge potential for several social media …
Dense Node Representation for Geolocation
November, 2019
Prior research has shown that geolocation can be substantially improved by including user network information. While effective, it …
Women’s Syntactic Resilience and Men’s Grammatical Luck: Gender-Bias in Part-of-Speech Tagging and Dependency Parsing
July, 2019
Several linguistic studies have shown the prevalence of various lexical and grammatical patterns in texts authored by a person of a …
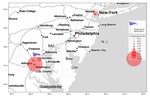
Peer networks and entrepreneurship: A Pan-African RCT
January, 2019
Can large-scale peer interaction foster entrepreneurship and innovation? We conducted an RCT involving almost 5,000 entrepreneurs from …
Predicting News Headline Popularity with Syntactic and Semantic Knowledge Using Multi-Task Learning
October, 2018
Newspapers need to attract readers with headlines, anticipating their readers’ preferences. These preferences rely on topical, …
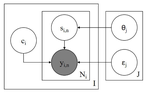
Comparing Bayesian Models of Annotation
October, 2018
The analysis of crowdsourced annotations in natural language processing is concerned with identifying (1) gold standard labels, (2) …
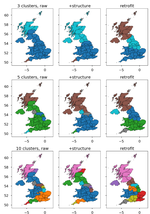
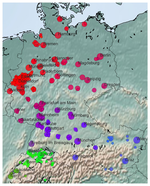
Capturing Regional Variation with Distributed Place Representations and Geographic Retrofitting
October, 2018
Dialects are one of the main drivers of language variation, a major challenge for natural language processing tools. In most languages, …
The Social and the Neural Network: How to Make Natural Language Processing about People again
June, 2018
Over the years, natural language processing has increasingly focused on tasks that can be solved by statistical models, but ignored the …