Comparing Bayesian Models of Annotation
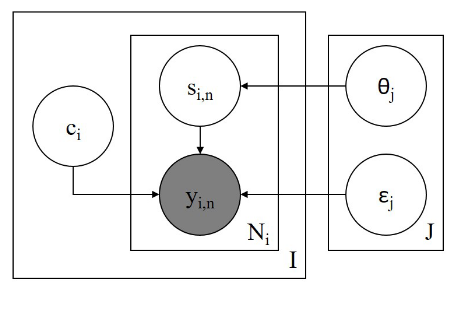 Diagram of MACE
Diagram of MACE
Abstract
The analysis of crowdsourced annotations in natural language processing is concerned with identifying (1) gold standard labels, (2) annotator accuracies and biases, and (3) item difficulties and error patterns. Traditionally, majority voting was used for 1, and coefficients of agreement for 2 and 3. Lately, model-based analysis of corpus annotations have proven better at all three tasks. But there has been relatively little work comparing them on the same datasets. This paper aims to fill this gap by analyzing six models of annotation, covering different approaches to annotator ability, item difficulty, and parameter pooling (tying) across annotators and items. We evaluate these models along four aspects: comparison to gold labels, predictive accuracy for new annotations, annotator characterization, and item difficulty, using four datasets with varying degrees of noise in the form of random (spammy) annotators. We conclude with guidelines for model selection, application, and implementation.