Capturing Regional Variation with Distributed Place Representations and Geographic Retrofitting
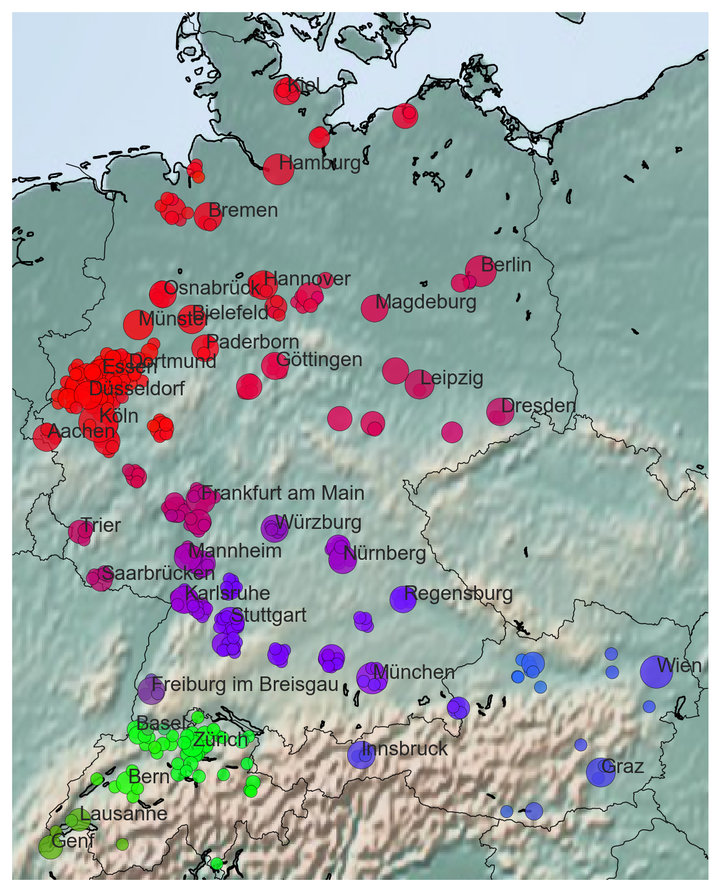 Learned Dialect Areas
Learned Dialect Areas
Abstract
Dialects are one of the main drivers of language variation, a major challenge for natural language processing tools. In most languages, dialects exist along a continuum, and are commonly discretized by combining the extent of several preselected linguistic variables. However, the selection of these variables is theory-driven and itself insensitive to change. We use Doc2Vec on a corpus of 16.8M anonymous online posts in the German-speaking area to learn continuous document representations of cities. These representations capture continuous regional linguistic distinctions, and can serve as input to downstream NLP tasks sensitive to regional variation. By incorporating geographic information via retrofitting and agglomerative clustering with structure, we recover dialect areas at various levels of granularity. Evaluating these clusters against an existing dialect map, we achieve a match of up to 0.77 V-score (harmonic mean of cluster completeness and homogeneity). Our results show that representation learning with retrofitting offers a robust general method to automatically expose dialectal differences and regional variation at a finer granularity than was previously possible.