Can Demographic Factors Improve Text Classification? Revisiting Demographic Adaptation in the Age of Transformers
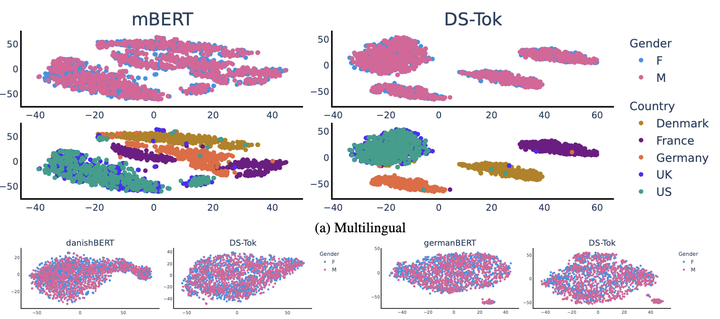 Separation by gender and country
Separation by gender and country
Abstract
Demographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating demographic factors can consistently improve performance for various NLP tasks with traditional NLP models. In this work, we investigate whether these previous findings still hold with state-of-the-art pretrained Transformer-based language models (PLMs). We use three common specialization methods proven effective for incorporating external knowledge into pretrained Transformers (e.g., domain-specific or geographic knowledge). We adapt the language representations for the demographic dimensions of gender and age, using continuous language modeling and dynamic multi-task learning for adaptation, where we couple language modeling objectives with the prediction of demographic classes. Our results, when employing a multilingual PLM, show substantial gains in task performance across four languages (English, German, French, and Danish), which is consistent with the results of previous work. However, controlling for confounding factors – primarily domain and language proficiency of Transformer-based PLMs – shows that downstream performance gains from our demographic adaptation do not actually stem from demographic knowledge. Our results indicate that demographic specialization of PLMs, while holding promise for positive societal impact, still represents an unsolved problem for (modern) NLP.