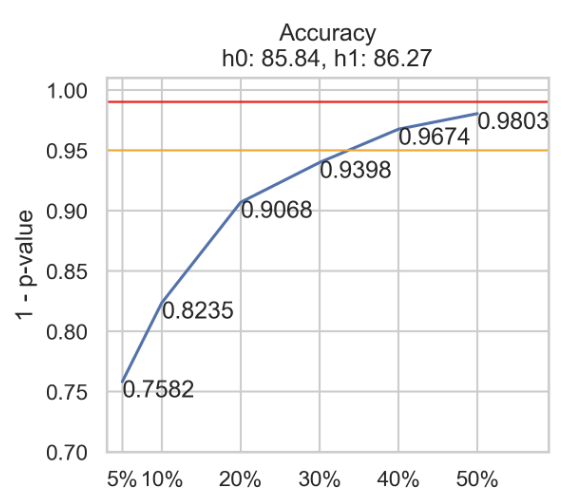
 p-levels with different sub samples
p-levels with different sub samples
Abstract
Natural Language Processing (NLP) ‘s applied nature makes it necessary to select the most effective and robust models. Producing slightly higher performance is insufficient; we want to know whether this advantage will carry over to other data sets. Bootstrapped significance tests can indicate that ability.So while necessary, computing the significance of models’ performance differences has many levels of complexity. It can be tedious, especially when the experimental design has many conditions to compare and several runs of experiments.We present BooStSa, a tool that makes it easy to compute significance levels with the BOOtSTrap SAmpling procedure to evaluate models that predict not only standard hard labels but soft-labels (i.e., probability distributions over different classes) as well.