Beyond Flesch-Kincaid: Prompt-based Metrics Improve Difficulty Classification of Educational Texts
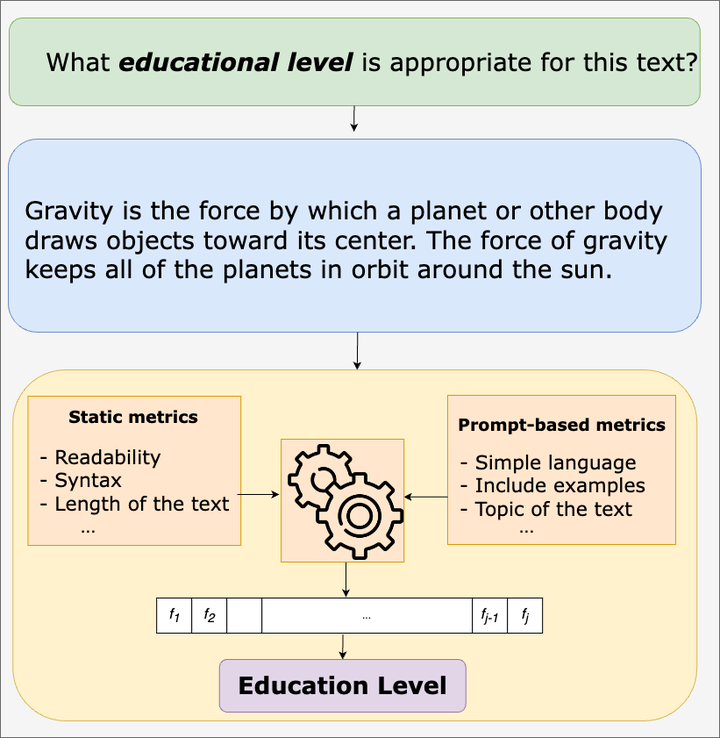 Combining static metrics with prompt-based metrics for classifying the difficulty of educational texts.
Combining static metrics with prompt-based metrics for classifying the difficulty of educational texts.
Abstract
Using large language models (LLMs) for educational applications like dialogue-based teaching is a hot topic. Effective teaching, however, requires teachers to adapt the difficulty of content and explanations to the education level of their students. Even the best LLMs today struggle to do this well. If we want to improve LLMs on this adaptation task, we need to be able to measure adaptation success reliably. However, current Static metrics for text difficulty, like the Flesch-Kincaid Reading Ease score, are known to be crude and brittle. We, therefore, introduce and evaluate a new set of Prompt-based metrics for text difficulty. Based on a user study, we create Prompt-based metrics as inputs for LLMs. They leverage LLM’s general language understanding capabilities to capture more abstract and complex features than Static metrics. Regression experiments show that adding our Prompt-based metrics significantly improves text difficulty classification over Static metrics alone. Our results demonstrate the promise of using LLMs to evaluate text adaptation to different education levels.