“You Sound Just Like Your Father” Commercial Machine Translation Systems Include Stylistic Biases
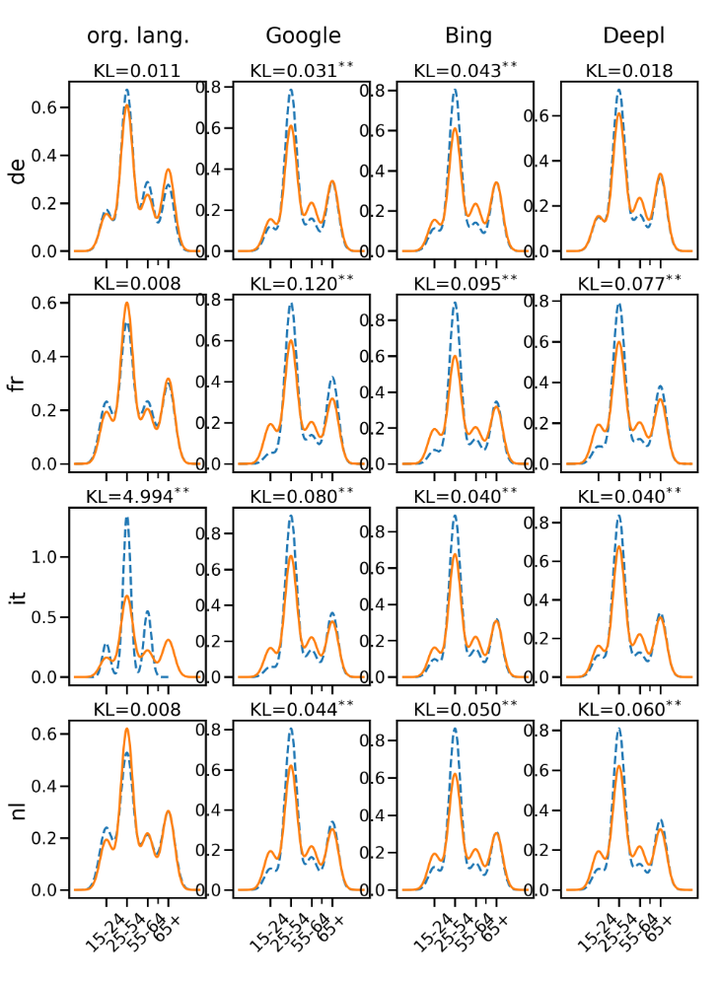 Age Differences before and after Translation
Age Differences before and after Translation
Abstract
The main goal of machine translation has been to convey the correct content. Stylistic considerations have been at best secondary. We show that as a consequence, the output of three commercial machine translation systems (Bing, DeepL, Google) make demographically diverse samples from five languages “sound” older and more male than the original. Our findings suggest that translation models reflect demographic bias in the training data. This opens up interesting new research avenues in machine translation to take stylistic considerations into account.
Type
Publication
ACL